

.png)
Historica's Latest Experiment Results: Using LLM for Feature Engineering in Historical Data
Updates in Historical Data Analysis
At Historica, we've been investigating the use of advanced AI technologies for enhancing historical data analysis, aiming to streamline and enrich the exploration of vast historical datasets. Currently, our primary objective is to empirically assess the viability of employing Large Language Models (LLMs) for the purpose of feature engineering within the domain of historical data, leveraging the approach outlined in our research framework.
Annotating Historical Texts
Automated annotation is a crucial step in analyzing textual data, particularly in historical research where precision is key. Traditional manual methods have been laborious, but with the evolution of ML/NLP technologies like language models, this process has become more efficient, allowing for quicker and more accurate analysis of large datasets. Besides manual labor, alternative approaches for annotating historical textual data include spaCy, NLTK, TextBlob, and StanfordNLP.
Experimentation and Evaluation
The primary task was to verify the hypothesis derived from the University of Barcelona's article. In our study, we compared several models to assess their performance in annotating historical texts. Criteria for evaluation included accuracy, completeness, consistency, latency, cost-effectiveness, and the reliability of results. Among the models tested, two emerged as the most effective, offering a balance of speed, accuracy, and reliability.
Models Overview
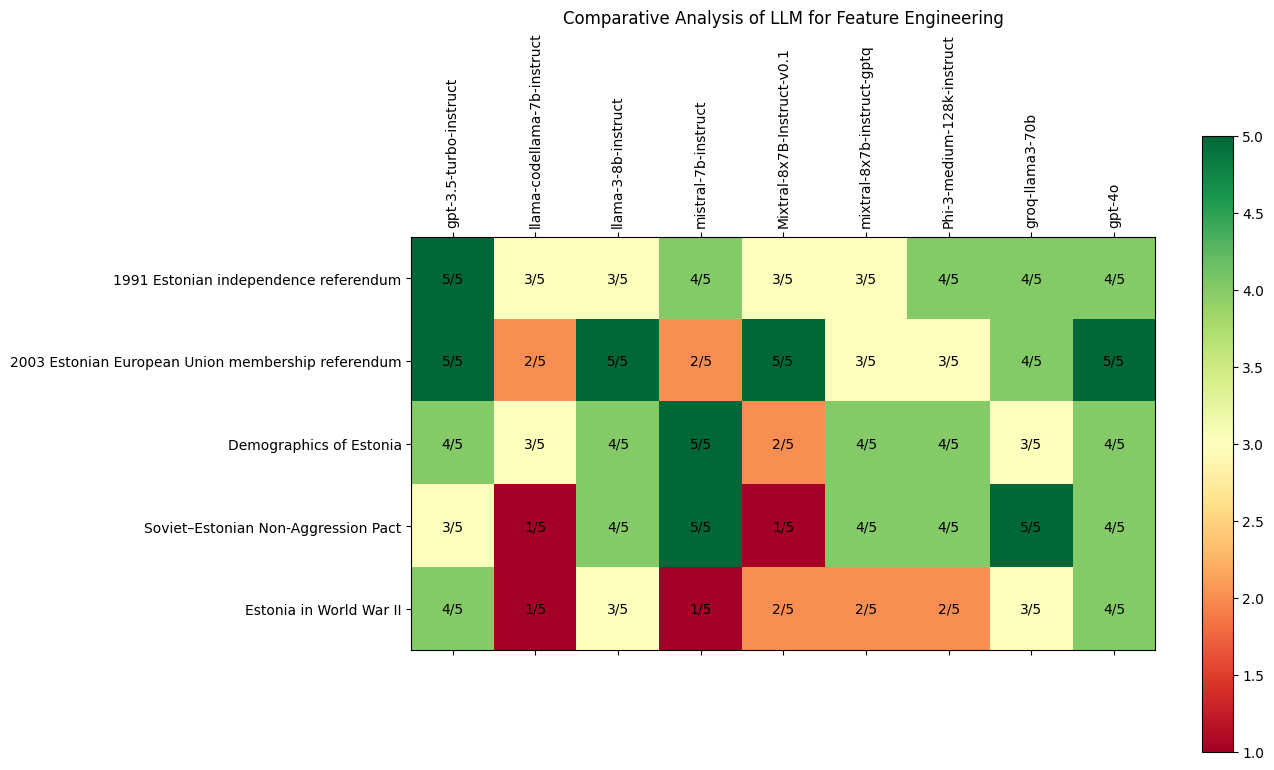
- GPT-3.5-turbo-instruct is reliable and efficient. This model consistently delivers high-quality annotations with moderate latency and cost-effectiveness, ideal for historical data tasks. It excels in maintaining annotation integrity.
- Llama-codellama-7b-instruct has weak Performance. Consistently below average, with high latency and moderate cost-effectiveness. It often produces hallucinations, reducing reliability.
- Llama-3-8b-instruct has variable performance. It shows potential in specific tasks but lacks consistency. Moderate latency and cost-effectiveness offset its performance.
- Mistral-7b-instruct is occasionally good, unstable. It delivers good results occasionally but lacks consistency, hindering automatic annotation.
- Mixtral-8x7B-Instruct-v0.1 shows mixed performance. It operates relatively quickly but lacks depth, limiting suitability for comprehensive annotation.
- Mixtral-8x7b-instruct-gptq: structured and effective. It has high accuracy, consistency, and relevance, with moderate latency and cost-effectiveness.
- Phi-3-medium-128k-instruct: consistently good. Delivers high-quality results consistently, suitable for research.
- Groq-llama3-70b: good and provides fast, high-quality responses, a top choice for similar tasks.
- GPT-4o: fast and offers high-quality responses, excellent for historical data annotation.
Data Collection for the Experiment
Data for the experiment were gathered from open historical sources. We randomly selected texts related to Estonia stored on Wikipedia. The data were standardized, resulting in five texts of varying lengths. Three texts had token counts (the smallest meaningful unit for LLMs) not exceeding 400, while the remaining two texts consisted of 2955 and 12488 tokens.
Challenges and Considerations
However, our study also encountered challenges, such as limitations in processing lengthy texts in some models. For our experiment, we aimed to compare several models from OpenAI and selected a few open-source models for a comprehensive evaluation. The criteria for selection included text generation quality, speed, and customization capability. We relied on the LLM Arena on Hugging Face to guide our choice of models. This raises questions about the best approach for large-scale historical data annotation tasks. Further exploration is needed to determine the optimal strategy.
Summary
GPT-4o and GPT-3.5-turbo-instruct stand out as top choices for historical data annotation, balancing speed, accuracy, and reliability. Llama-3 and Phi-3 also perform well. However, other models need refinement to meet high standards for dependable annotation.
Our experiment uncovered pitfalls in model comparison, notably the limitations of context windows. This prompts a key debate: Should we generate multiple responses from a model for different parts of a text and integrate them, requiring more resources? Or should we prefer a single, comprehensive response from a model analyzing the entire text at once, risking some information omission?
This trade-off between resource allocation and the risk of data loss requires further investigation to identify the optimal strategy for large-scale historical data annotation tasks.


.webp)